



1. Теория
Задача — найти ключевые слова по теме авиабилетов с трафиком и низкой конкуренцией. Большинство вебмастеров используют для этого Вордстат с устаревшей информацией. Но Яндекс говорит, что в большей части поисков используются запросы, которые задаются впервые.
В статье мы постараемся предугадать запросы пользователей.
2. Структура сайта
Чтобы охватить максимум семантики, используем следующую структуру сайта:

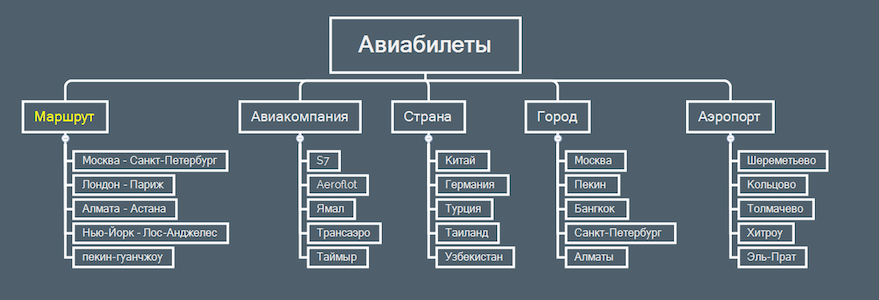
Сначала соберем ключевые слова для раздела «Маршруты». Чаще всего пользователи задают запросы с названиями двух городов, когда ищут авиа- и ж/д-билеты. Ключевое слово будем использовать в разделе «Маршруты», если в запросе присутствуют названия двух городов.
3. Сбор «масок»
Далее нам нужна информация по авиа-маршрутам в виде «город вылета — город прилета». Логика следующая — если между городами есть маршруты, то пользователи ищут по ним авиабилеты.
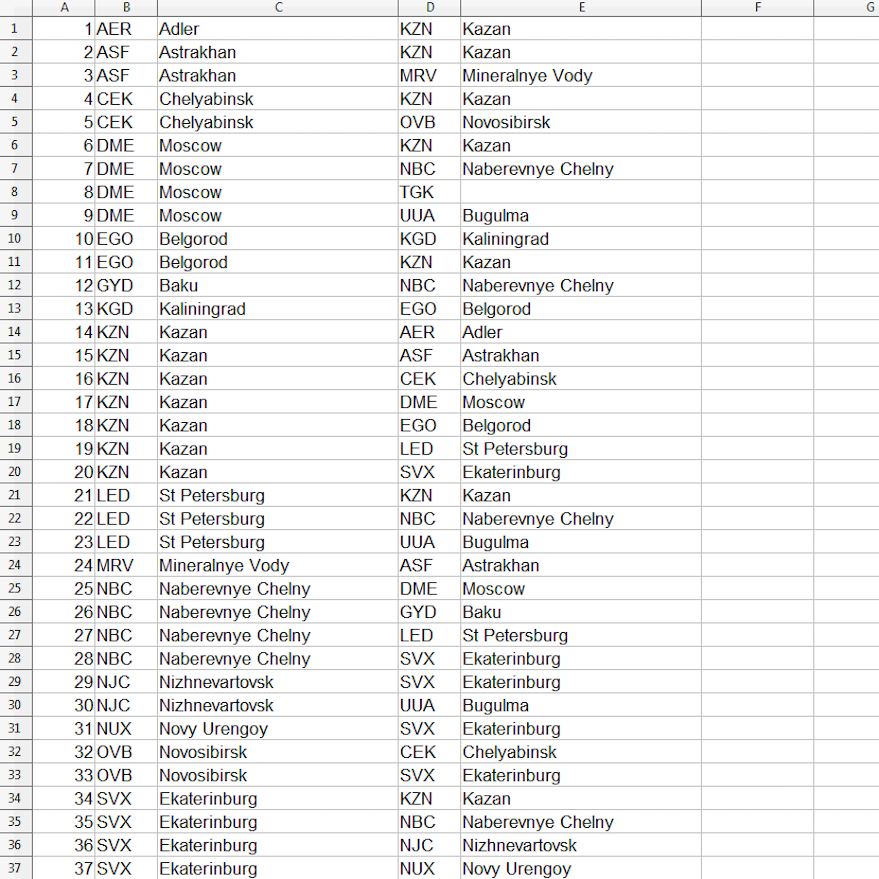
Скачиваем список 72 381 авиа-маршрутов из Авиасейлз (спасибо за него Travelpayouts). Оставляем столбец с кодами IATA аэропортов вылета и прилета.
Скачиваем с сайта apinfo.ru русскоязычную базу со всеми гражданскими аэропортами мира. Оставляем столбцы с кодами ИАТА и названиями городов на английском.Также можно использовать готовые json Travelpayouts, в которых есть данные на нескольких языках (api.travelpayouts.com, в самом низу).
Пишем скрипт, который подставляет название городов в таблицу с маршрутами и экспортируем CSV-таблицу:

4. Перевод названий городов на русский язык
Т.к. база apinfo.ru не содержит названий на русском — переведем их самостоятельно. Копируем два столбца с городами в таблицу Гугл Докс. Переводим названия городов на русский, используя функцию GOOGLETRANSLATE:

5. Очистка переведенных названий
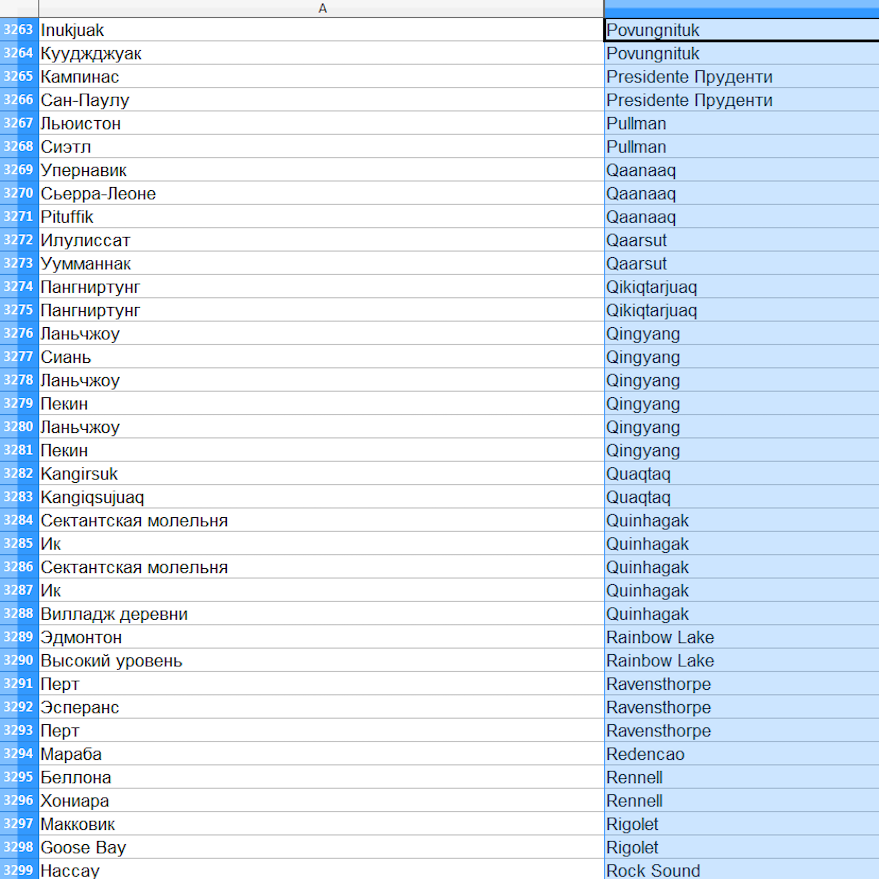
В процессе сбора будет много неверно переведенных запросов («Anchorage — Якорная стоянка»), пустых строк и т.д. Но цель способа — обработать большое количество информации, поэтому не обращаем внимание на погрешность.
Используя сортировку по алфавиту удаляем строки, в которых есть пустые ячейки и маршруты с городами на английском:
6. Сбор частотности запросов
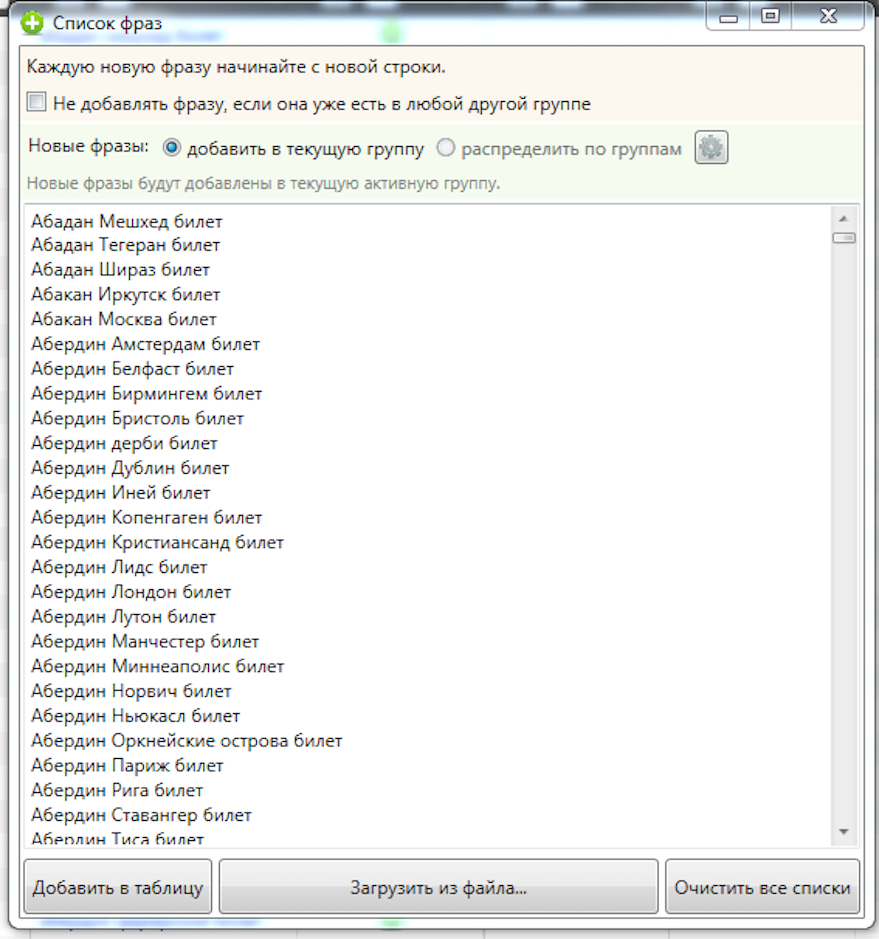
Далее определяем маршруты, которые ищут пользователи в поисковиках. Для этого собираем частотности пар городов из Вордстата и конкуренцию в КейКоллекторе.
Добавляем к каждой паре слово «билет», чтобы быть уверенными, что пользователи ищут эти ключевые слова при поиске авиабилетов:

Собираем общую частотность:

Удаляем запросы с частотностью ниже пяти и больше тысячи:

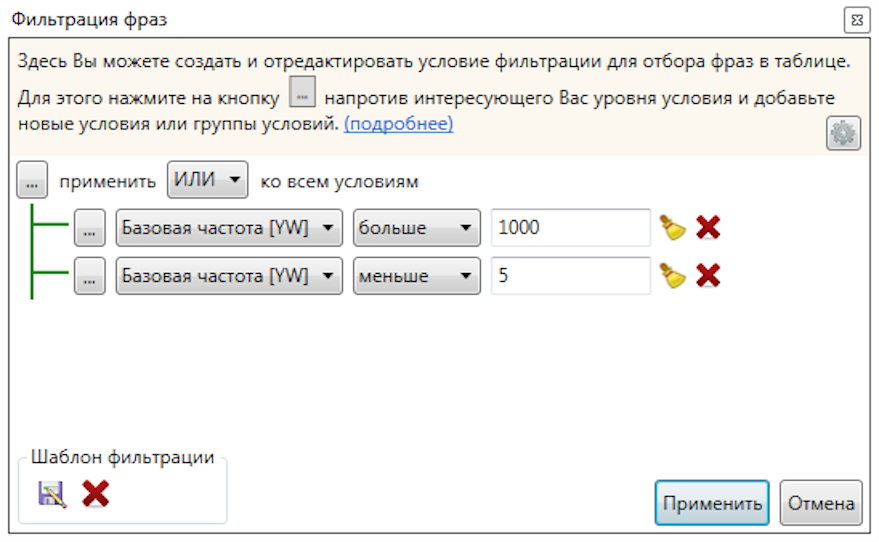
7. Определение конкуренции запросов
Определяем конкуренцию запросов через индекс конкуренции ключевых слов (KEI). Чем меньше значение — тем ниже конкуренция по ключевому слову. При низком значении индекса запроса можно быстро попасть в ТОП.
Используем формулу: KEI = (главных страниц в ТОПе)3 + (точных вхождений ключа в Title в ТОПе)3
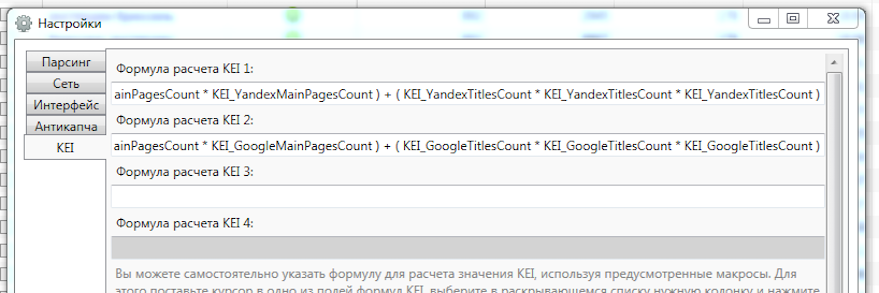
Вводим формулы для расчета KEI 1 и KEI 2 в в настройках КейКоллектора:
Для Яндекса:
( KEI_YandexMainPagesCount * KEI_YandexMainPagesCount * KEI_YandexMainPagesCount ) + ( KEI_YandexTitlesCount * KEI_YandexTitlesCount * KEI_YandexTitlesCount )
Для Google:
( KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount ) + ( KEI_GoogleTitlesCount * KEI_GoogleTitlesCount * KEI_GoogleTitlesCount )

Собираем данные для Яндекса и Гугла, затем рассчитываем KEI:

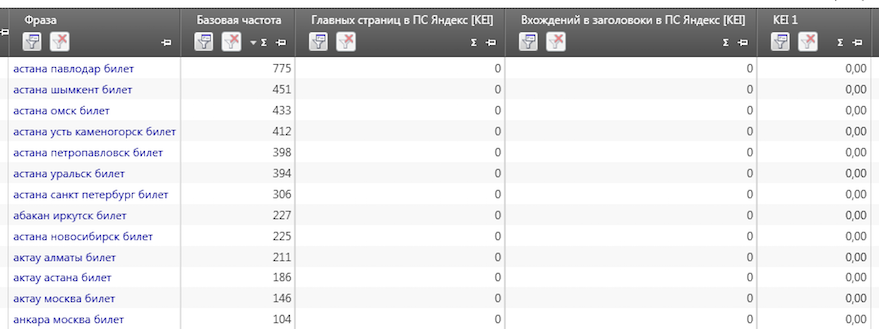
8. Сводная таблица
Экспортируем информацию с частотностью и конкуренцией запросов в итоговую таблицу с кодами ИАТА:

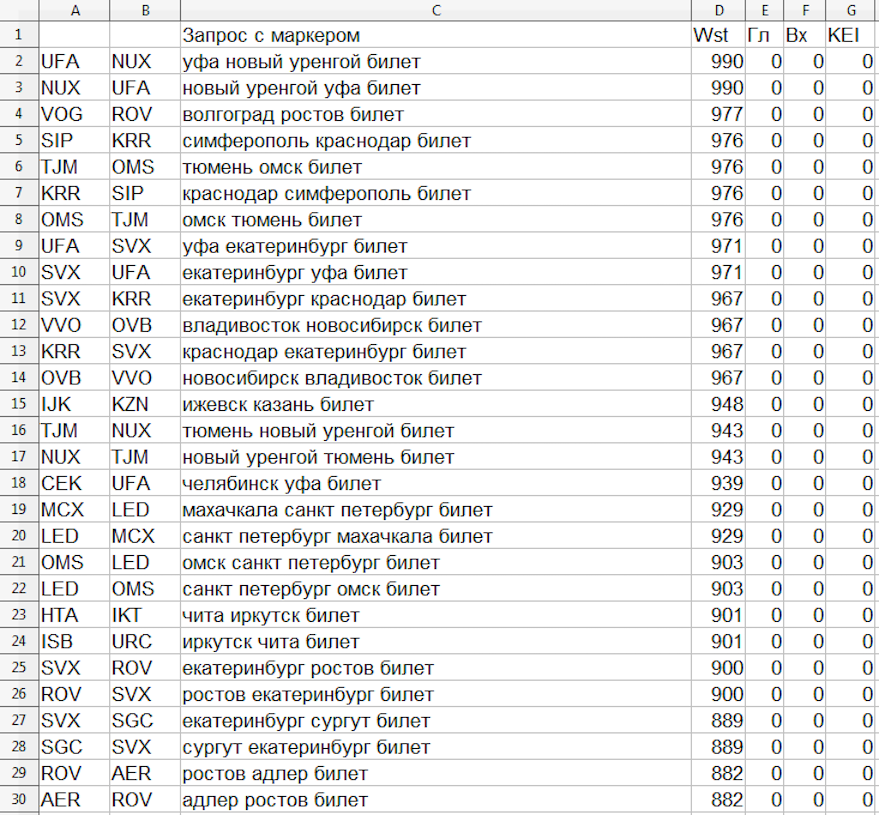
Скачать таблицу 6 331 направлений с трафиком и низкой конкуренцией.
9. Определение интентов (намерений пользователей)
Далее постараемся предугадать вопросы, которых интересуют пользователей в контексте поиска авиабилетов. В Travelpayouts уже подобрали интенты («Авиабилеты — Семантическое ядро.xlsx»):

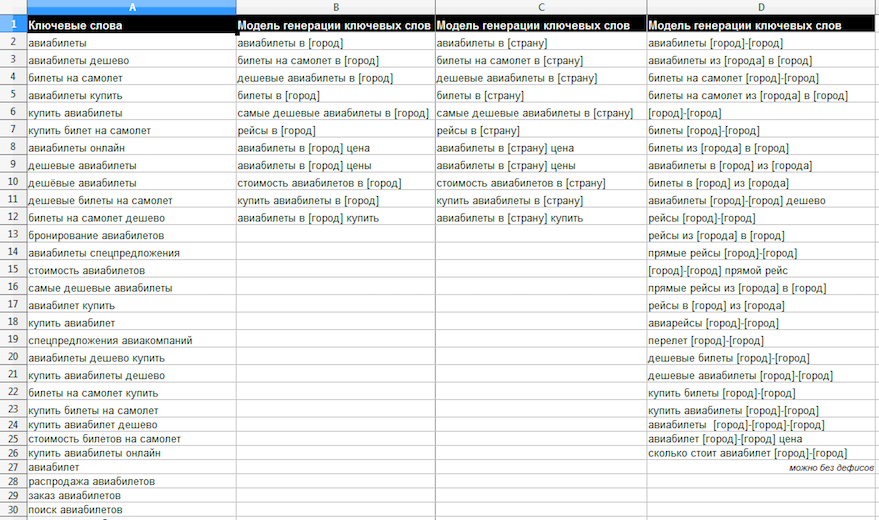
На следующих шагах из интентов мы будем составлять ключевые слова для посадочных страниц.
10. Выводы
- Не нужно гнаться за ВЧ-запросами. Много трафика дают НЧ-запросы
- Нулевое значение KEI показывает отсутствие или низкую конкуренцию запроса
- Использование интентов на странице позволяет привлечь больше трафика по УНЧ-запросам
11. Что дальше?
Мы собрали семантическое ядро с трафиком и низкой конкуренцией. В данном примере мы сделали это для русскоязычных запросов, но вы можете пойти дальше и сделать такую же подборку на других языках. В следующих статьях мы поговорим о генерации посадочных страниц, контенте и оптимизации на основе полученных данных.
Статью подготовил Виталий Виноградов. Продвигаю личные и клиентские сайты с 2005 года. Сейчас консультирую по SEO и настраиваю контекстную рекламу. Обращайтесь — https://vinograd.io!